Background
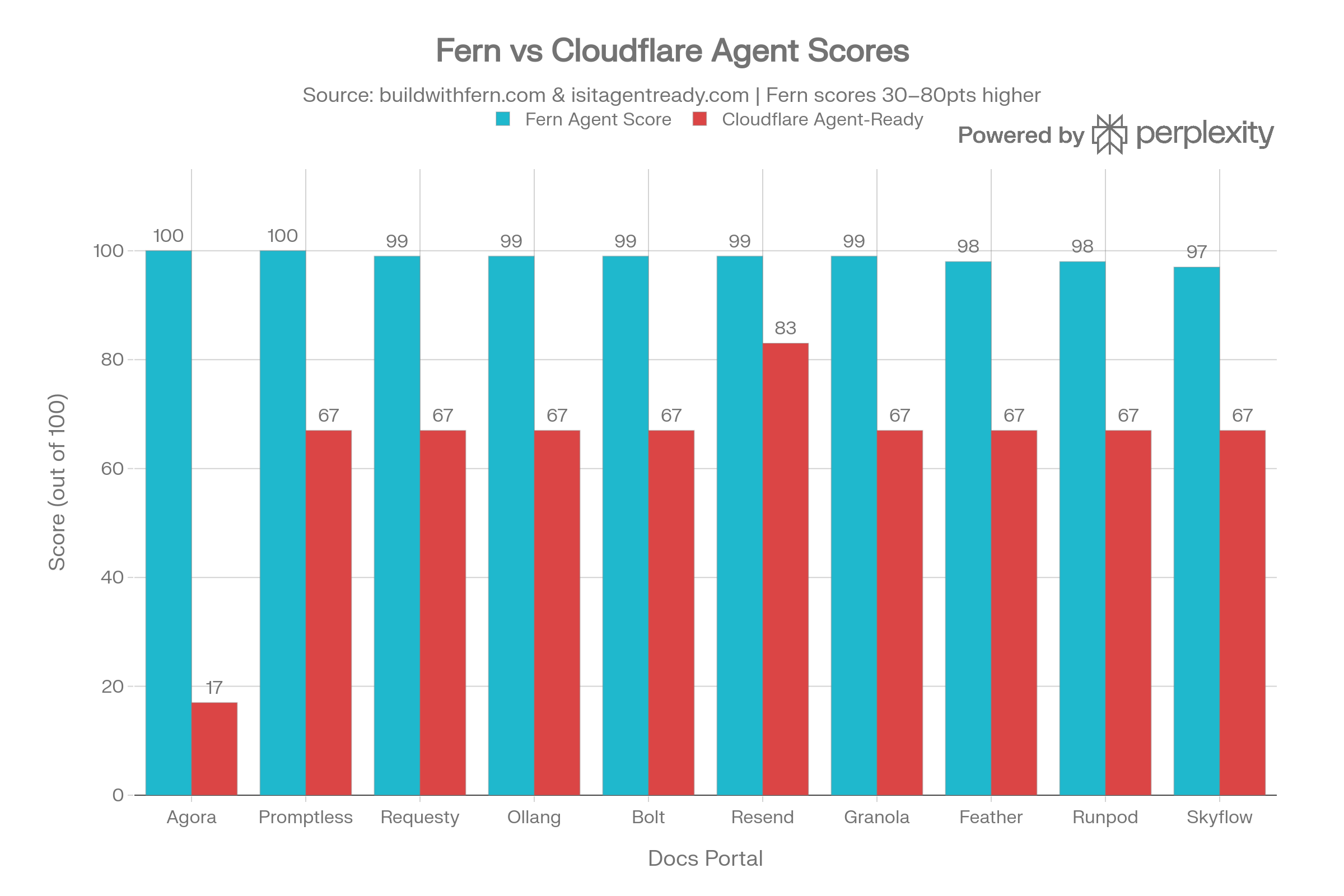
Fern publishes a leaderboard of the top documentation portals based on their agent-friendliness. Of these, I picked the top 10 portals and ran them through Cloudflare’s Is Your Site Agent-Ready? tool. Here are the top 10 portals from Fern’s leaderboard and their scores:Approach
Cloudflare’s Is Your Site Agent-Ready? tool offers three types of scans:- All checks: Run all default checks. Best for comprehensive audits.
- Content Site: Run checks relevant to content sites. Focuses on discoverability and content accessibility.
- API / Application: Run checks relevant to API / Application sites, except commerce.
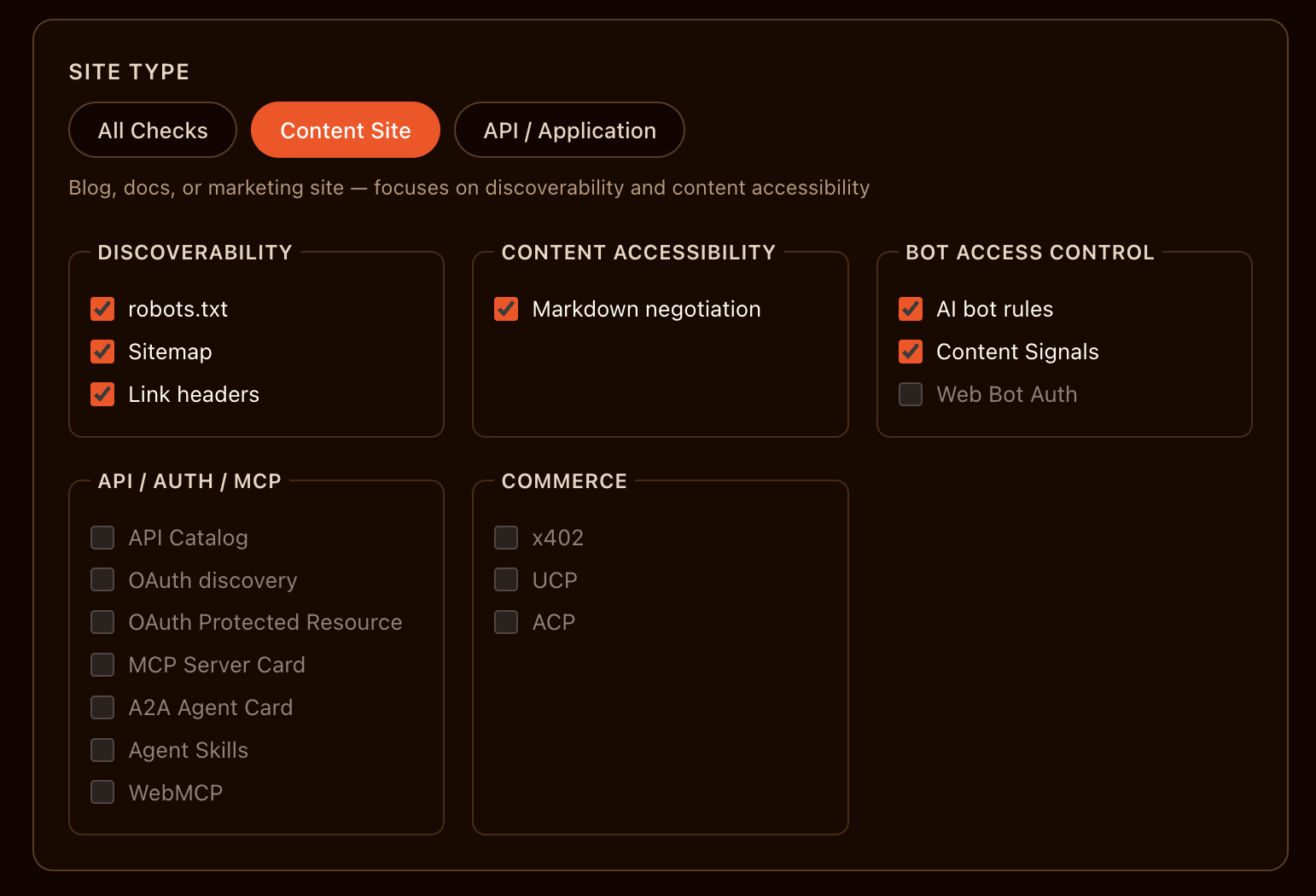
Cloudflare content site checks
Results
The results were quite surprising. None of the portals scored above 90, with Resend coming closest at 83. Here is how the scores compare side by side:Cloudflare’s own developer documentation scores 100 on Is Your Site Agent-Ready? and 97 on Fern’s Agent Score.
Understanding the results
The scores are clearly different, but why are they so different? To find out, I looked at how these tools suggest improvements. Both Fern and Cloudflare offer an agent prompt to fix the issues they flag. The idea was to understand common patterns that both tools flag and where their suggestions diverge. I copied the suggestions from Fern and Cloudflare, exported them as Markdown, and ran them through Claude Sonnet 4.6 Thinking via Perplexity.Prompt
Prompt
Fern_Cloudflare_agent_score_comparison.csv contains comparison between the agent scores from Fern’s agent score checker (https://buildwithfern.com/agent-score) and Cloudflare’s Is Your Site Agent-Ready? (https://isitagentready.com/).Cloudflare_agent_readiness_improvement_suggestions.md and Fern_agent_readiness_improvement_suggestions.md contain suggestions from Cloudflare and Fern to improve agent scores respectively.Based on this data, find out:
- Why do the scores differ vastly?
- What is the common pattern in the suggestions from Fern and Cloudflare?
- Which change has the greatest ROI?
- What are the key takeaways? Analyze the findings and share an executive summary.
Executive summary
Executive summary
The two tools measure fundamentally different dimensions of “agent readiness”, which is why scores diverge so dramatically — Fern scores cluster in the 97–100 range while Cloudflare scores range from 17 to 83. The gap is not a measurement error; it reflects two distinct philosophies: content accessibility vs. web infrastructure governance.
1. Why the Scores Differ Vastly
1. Why the Scores Differ Vastly
The tools operate on completely different evaluation frameworks:Fern (buildwithfern.com/agent-score) measures how well an AI agent can read and consume your documentation content. Its checks focus on:
- Whether
llms.txtexists and is properly structured - Whether pages serve clean Markdown (
.mdURLs, content negotiation viaAccept: text/markdown) - Whether page content starts early (low boilerplate ratio)
- Whether Markdown and HTML representations are in parity (no hidden JS-only content)
- Whether sitemaps exist for discovery
- Whether
robots.txtexists with explicit AI crawler rules (GPTBot, Claude-Web, Google-Extended) - Whether the site supports Markdown for Agents (HTTP content negotiation returning
text/markdown) - Whether RFC 8288 Link headers are present for agent discovery
- Whether Content Signals (
ai-train=no/yes,ai-input=no/yes) are declared inrobots.txt - Whether
sitemap.xmlexists with canonical URLs
2. Common Patterns in Both Sets of Suggestions
2. Common Patterns in Both Sets of Suggestions
Both tools converge on two themes: structured content discoverability and clean machine-readable responses.
The single most universal gap across both tools is the absence of machine-readable content negotiation — every site either lacks
.md URLs, a proper Markdown response header, or both.3. Change with the Greatest ROI
3. Change with the Greatest ROI
Enabling Markdown content negotiation and adding
Content Signals to robots.txt offer the highest ROI, and here’s why:-
Markdown content negotiation (
Accept: text/markdown): Both Fern and Cloudflare flag this. On the Fern side, it eliminates theMarkdown Content Paritywarning (affects 2–3 pages on most sites). On Cloudflare’s side, it converts a hard fail into a pass for the “Markdown for Agents” check. Enabling this via a CDN/middleware rule is typically a single configuration change. -
Content Signalsinrobots.txt: This is flagged as a failing check on every single site across all 10 in Cloudflare’s report. It requires a one-line edit to an existing file (Content-Signal: ai-train=no, search=yes, ai-input=no) — zero engineering effort, but unlocks Cloudflare’s governance score immediately. -
RFC 8288 Link headers: Flagged on 8/10 sites by Cloudflare. Adding
Link: </.well-known/api-catalog>; rel="api-catalog"at the server/CDN level is a one-time header rule that immediately improves agent discovery.
4. Key Takeaways
4. Key Takeaways
- Two tools, two different definitions of “ready”: Fern assesses content quality and LLM-specific formats; Cloudflare assesses governance, HTTP standards, and web infrastructure. You need both to be truly agent-ready — a site can score 99 on Fern while being woefully unprepared on the Cloudflare dimensions.
- Agora is the most egregious outlier: It scores 100 on Fern but only 17 on Cloudflare — it has excellent documentation content but zero infrastructure governance (no
robots.txt, no sitemap, no AI rules). A perfect content score is meaningless if agents can’t determine whether they’re allowed to use the content. - The “67 plateau” on Cloudflare is structural: Eight out of ten sites share the exact same Cloudflare score of 67. This strongly suggests they’re all passing the same baseline checks (e.g.,
robots.txtexists, sitemap exists) but uniformly failing the newer governance checks (Content Signals,Link headers). This is an industry-wide blind spot, not a site-specific issue. llms.txtquality is a near-universal Fern warning: Even sites scoring 98–99 on Fern havellms.txtfiles that are missing the blockquote summary required by the spec. Fixing this is trivial — add a> Brief summary of the docsline to the file.- The highest-scoring site overall is Resend (99 Fern, 83 Cloudflare), suggesting it has implemented more of the infrastructure-level signals. It serves as the benchmark to emulate.
Conclusion
As AI agents increasingly become the primary consumers of documentation, being truly agent-ready must evolve beyond just writing clean, well-structured content. While having high-quality documentation is foundational (as measured by Fern), adopting proper web infrastructure protocols and governance (as measured by Cloudflare) is the next major frontier for developer platforms. The current industry-wide blind spot regarding machine-readable content negotiation andContent Signals presents a massive opportunity. Documentation teams that proactively bridge this gap by aligning both their content structures and their infrastructure layer won’t just score higher on these evaluations, they’ll ensure their APIs are the easiest for autonomous agents to discover, understand, and integrate with.
Dachary Carey has now published a companion investigation where she measures the adoption of Cloudflare’s standards against actual agent traffic to highlight how agents consume docs today.
Resources
Test with Fern
Run your docs through Fern’s Agent Score and share your results.
Test with Cloudflare
Check your site’s infrastructure readiness with Cloudflare’s Is Your Site Agent-Ready?
Analysis resources
Google Drive folder with all the data and files used in this analysis.
Share your feedback
Did you find this useful? Have a different take on the results? I’d love to hear from you.Contact me
Reach out with feedback, corrections, or suggestions.
Connect on LinkedIn
Follow me on LinkedIn for more posts like this.